- A
- A
- A
- ABC
- ABC
- ABC
- А
- А
- А
- А
- А
Researchers from HSE University and Artificial Intelligence Research Institute Train Neural Network to Learn Much More Efficiently
ISTOCK
Neural network generative models have achieved impressive results in recent years, but researchers are still working on increasing their efficiency. Researchers from the HSE Faculty of Computer Science and AIRI have managed to optimize the finetuning of the StyleGAN2 neural network, which creates realistic images, to new domains, reducing the number of trained parameters by four orders of magnitude. At the same time, the quality of the obtained images remained high. The results of this work were presented at the NeurIPS 2022 conference.
Modern models can generate human faces so well that we can’t distinguish them from the faces of real people, and at the same time all of these faces are new, that is, such people have never existed. GAN (Generative Adversarial Network), a generative adversarial network, has become one of the most promising types of generative models. This is a combination of two neural networks, one of which (the generator) produces samples, and the other (the discriminator) tries to distinguish correct samples from incorrect ones. Since the generator and the discriminator have opposite goals, they begin to play out an antagonistic game, which contributes to the rapid achievement of a common goal — the creation of a realistic image.
The main problem in training generative models is collecting a large number of high-quality images. In order to learn how to generate realistic faces in high resolution, the network will need to process about 100,000 different faces. Unfortunately, it is difficult to assemble this kind of dataset, especially in some situations when, for example, you need portraits in the style of a particular artist or characters from the Pixar universe.
However, even in extreme cases, when several examples of stylized images or only text descriptions are available, there are methods for finetuning the generative model, which was initially based on a large dataset of ordinary images.
Previously, to adapt the generator to a new domain (for example, Pixar-style portraits) we would finetune almost all the parameters—about 30 million. Our goal was to reduce their number, since we understood that it did not make sense to re-train the entire generator in order to change only the style of the previously created image.
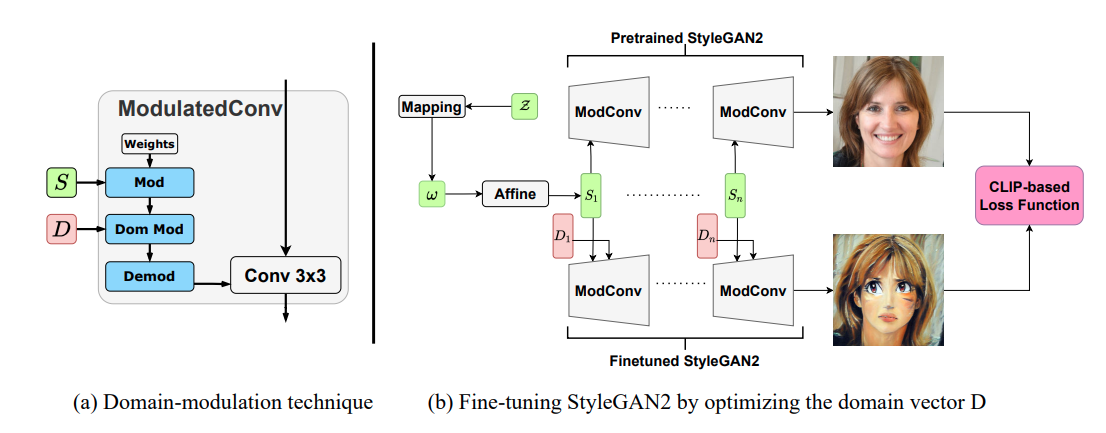
In the article ‘HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks’, researchers from the HSE Centre of Deep Learning and Bayesian Methods described a new approach to retraining the generative StyleGAN2 model. This is a generative neural network that converts random noise into a realistic picture. The researchers managed to optimize its adaptation to new domains by reducing the number of trained parameters (weights) by four orders of magnitude by training an additional domain vector.
{kind=link}
The architecture of the StyleGAN2 network implies special transformations (modulations) by which the input random vector controls the semantic features of the output image, such as gender, age, etc. The researchers proposed to train an additional vector that defines the domain of the output images through similar modulations.
If we additionally finetune only this domain vector, then the domain of the generated images changes just as well as if we had retrained all the parameters of the neural network. This drastically reduces the number of optimized parameters, since the dimension of such a domain vector is only 6000, which is orders of magnitude less than 30 million weights of our generator.
Aibek Alanov
First author of the article, Research Assistant at the Centre of Deep Learning and Bayesian Methods, AIRI Research Fellow
{kind=link}
Taking into account the results, the researchers proposed the first method of multi-domain adaptation, which allows the model to be adapted to several domains simultaneously. This significant optimization of finetuning to new domains reduces the training time and memory used. Through this method, you can train a hypernet that has fewer parameters than the original generator, but stores hundreds or even thousands of new domains.
IQ
Dmitry Vetrov
Head of the Centre of Deep Learning and Bayesian Methods, AIRI Leading Research Fellow