- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
В России нейросетям помогли лучше ориентироваться в пространстве
Исследователи из НИУ ВШЭ, НИТУ МИСиС и Института искусственного интеллекта AIRI нашли способ эффективнее проводить обучение с подкреплением для нейросетей, заточенных на ориентацию в пространстве. С помощью механизма внимания эффективность работы графовой нейросети увеличилась на 15%. Результаты исследования опубликованы в журнале IEEE Access.
В исследовании использовались ресурсы Программы фундаментальных исследований НИУ ВШЭ и вычислительные ресурсы HPC-кластера НИУ ВШЭ.
Одним из самых перспективных направлений применения роботов является логистика: машины, которые могут сами перенести коробку из точки A в точку B, беспилотные грузовики и дроны-доставщики, способные обходить препятствия на улицах городов. Для ориентации в трёхмерном пространстве таким устройствам (агентам) обязательно нужны нейросети, ведь окружающая среда требует быстрой реакции на изменяющиеся условия.
Если мы хотим научить агента действовать самостоятельно, то должны оценивать его работу в процессе обучения. Нельзя просто дать ему проблему и наблюдать — практически всегда она будет решена не тем образом и не с тем результатом, которого мы хотим. Поэтому нейросеть получает бонусный квест: при выполнении задачи набрать как можно больше очков. Очки даются за продвижение к оптимальному решению. Это и есть обучение с подкреплением. Пока нейросеть обучается, выполняя одно и то же задание много раз, мы оцениваем её результаты и либо поощряем «наградой» за движение в нужном направлении, либо признаем результат вредным и уменьшаем количество заработанных «очков».
Ориентирование в пространстве — одна из самых сложных задач в мире нейросетей. Проблема в том, что у нейросети зачастую нет полной информации о её текущем окружении, например, глубины или карты местности. Ещё меньше нейросеть знает о перспективах награды: вознаграждение выдается не поэтапно, а один раз в конце, после полного выполнения задания.
Представьте, что вам нужно пройти через лес к башне, заинтересовав как можно больше белок. Важно, что они сидят в основном на самом коротком пути (на пути оптимального решения) и, если увидят вас, пойдут за вами. При этом вы их не видите, где башня — не знаете и количество заинтересовавшихся вами зверей узнаете, только достигнув цели. Такого типа задачи достаются пространственным нейросетям.
Получение награды выражено математически функцией вознаграждения, и нейросеть должна определить её как можно точнее, чтобы максимизировать выигрыш. Хорошая функция помогает сети эффективнее решать задачу и обучаться.
Авторы исследования предложили новый метод формирования функции вознаграждения с учётом специфики однократного получения награды после полного решения проблемы. Он основывается на дополнительных вторичных выигрышах — шейпинге вознаграждения.
Учёные применили два способа улучшения техники, которую в 2020 году предложили канадские специалисты из Макгиллского университета. Первый использует продвинутые агрегирующие функции, а второй — механизм внимания. Продвинутые агрегирующие функции учитывают, в каком порядке и что видит нейросеть. В статье указывается на важность подбора агрегирующей функции под архитектуру конкретной нейросети.
Механизм внимания позволяет модели сосредоточиться на наиболее важных входных данных при создании прогнозов. Признаки важного, выгодного решения нейросеть находит при сопоставлении последовательных шагов решения задачи.
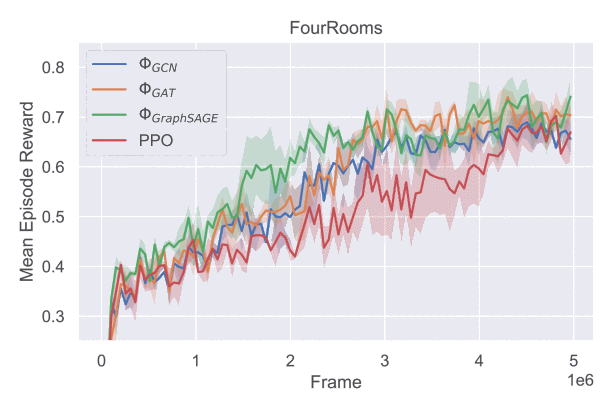
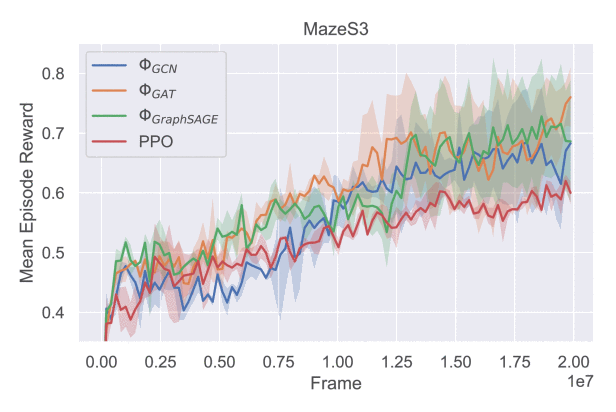
Исследователи провели серию экспериментов с поэтапным или разреженным вознаграждением (sparse reward). В ходе них использовали задачи на ориентацию в виртуальных пространствах «Четыре комнаты» и «Лабиринт».
{kind=link}
{kind=link}
В «Четырёх комнатах» нейросеть должна была обнаружить красный ящик, который случайным образом появлялся в одном из помещений. Нейросеть могла перемещаться только прямо, влево или вправо. Ящик — цель механизма внимания. Нейросеть обучалась параллельно в 16 таких пространствах, совершив пять миллионов действий.
А в задаче «Лабиринт» помещённый в произвольную точку агент должен найти выход. Сам лабиринт каждый раз генерируется случайным образом, поэтому для успешного обучения модели требуется пройти 20 миллионов шагов.
{kind=link}
{kind=link}
Исследование показало, что при формировании функции вознаграждения на основе механизма внимания агент обучается сосредотачиваться на рёбрах графа, соответствующих важным переходам в трёхмерной среде — тем, при которых цель попадает в поле зрения агента. Это до 15% повышает эффективность работы нейросетей.
Нам важно было оптимизировать процесс обучения именно для графовых нейронных сетей. Граф нельзя наблюдать целиком напрямую, но для эффективного обучения графовой нейронной сети достаточно рассматривать его части. Их можно наблюдать в виде отдельных траекторий перемещения агента. Таким образом, для обучения необязательны все варианты траекторий. Применение механизма внимания — перспективное решение, поскольку оно существенно ускоряет процесс обучения. Ускорение происходит за счёт учета структуры графа марковского процесса, что недоступно неграфовым нейросетям.
Илья Макаров
Доцент факультета компьютерных наук и приглашённый преподаватель Лаборатории алгоритмов и технологий анализа сетевых структур НИУ ВШЭ в Нижнем Новгороде, руководитель группы «ИИ в промышленности» Института искусственного интеллекта AIRI, директор Центра ИИ МИСиС
IQ
Матвей Герасёв
Один из авторов статьи, аспирант факультета компьютерных наук НИУ ВШЭ