- A
- A
- A
- АБB
- АБB
- АБB
- А
- А
- А
- А
- А
Тематическое моделирование для миллионов (гуманитариев)
ISTOCK
В Высшей школе экономики уже много лет активно развиваются самые современные направления и подходы к исследованиям, например, Digital Humanities — применение различных цифровых методов в гуманитарных науках. Они позволяют совершенно по-новому ставить и решать классические задачи, вроде установления авторства тех или иных произведений, а также работать с большими массивами текстовой информации, выявлять в них скрытые закономерности или количественно подтверждать известные факты. Одним из ведущих специалистов в этих проблемах является доцент факультета гуманитарных наук НИУ ВШЭ, основатель крайне интересного телеграм-канала о древних языках и античной культуре и философии Antibarbari HSE, Ольга Алиева. По просьбе редакции IQ.HSE в своей авторской колонке она рассказала, что такое алгоритм латентного размещения Дирихле (Latent Dirichlet Allocation, LDA) и как он используется в различных отраслях гуманитарного знания.
Ольга Алиева,
доцент факультета гуманитарных наук НИУ ВШЭ
Автор благодарит Бориса Орехова и Владислава Тереховича за помощь в подготовке материала и приглашает читателей к обсуждению на канале RAntiquity.
Что такое латентное размещение Дирихле?
Тематическое моделирование — семейство методов обработки больших коллекций текстовых документов. Эти методы позволяют определить, к каким темам относится каждый документ и какие слова образуют каждую тему.
Одним из таких методов является латентное размещение Дирихле (Latent Dirichlet Allocation, LDA). Так называется вероятностная модель, которая позволяет выявить заданное количество тем в корпусе текстов. В основе метода лежит предположение, что каждый документ представляет собой комбинацию ограниченного числа топиков (тем), а каждый топик — это распределение вероятностей для слов. При этом, как и в естественном языке, документы могут перекрывать друг друга по темам, а темы — по словам. Например, слово «мяч» может быть связано не только со спортивным топиком, но и, например, с политическим («клятва в зале для игры в мяч»). Создатели метода поясняют это на примере публикации из журнала Science (Рис. 1).
Рисунок 1. Основные принципы алгоритма латентного размещения Дирихле
'Introduction to Probabilistic Topic Models' David M. Blei
На картинке голубым выделена тема «анализ данных»; розовым — «эволюционная биология», а жёлтым — «генетика». Если разметить все слова в тексте (за исключением «шумовых», таких как союзы, артикли и т.п.), то можно увидеть, что документ представляет собой сочетание нескольких тем. Цветные «окошки» слева — это распределение вероятностей для слов в теме. Гистограмма справа — это распределение вероятностей для тем в документе. Все документы в коллекции представляют собой сочетание одних и тех же тем — но в разной пропорции. Так, в этом примере почти нет зелёного «текстовыделителя», что хорошо видно на гистограмме.
Алгоритм латентного размещения Дирихле рассчитывает ассоциацию слов с темами и тем с документами. При этом LDA относится к числу методов машинного обучения без учителя (unsupervised machine learning), то есть не требует предварительной разметки корпуса: система сама «находит» скрытые в корпусе темы и аннотирует каждый документ. Это делает метод востребованным в тех случаях, когда мы сами точно не знаем, что ищем — например, в исследованиях электронных архивов.
Сложность при построении модели обычно заключается в том, чтобы установить оптимальное число тем: для этого предлагались различные количественные метрики, однако важнейшим условием является интерпретируемость результата. Единственно правильного решения здесь нет: например, моделируя архив газетных публикаций, мы можем подобрать темы так, чтобы они примерно соответствовали рубрикам («спорт», «политика», «культура» и т.п.), но в некоторых случаях бывает полезно сделать zoom in, чтобы разглядеть отдельные сюжеты (например, «фигурное катание» и «баскетбол» в спортивной рубрике…)
Латентное размещение Дирихле в области истории науки и философии
Алгоритм LDA применялся историками философии и науки для изучения диахронных тематических сдвигов в различных отраслях. Так, команда канадских исследователей из Университета Квебека в Монреале опубликовала в 2019 году исследование, посвященное понятию «философия науки».
Чтобы ответить на вопрос о том, что такое «философия науки», они смоделировали архив журнала Philosophy of Science с 1934 по 2015 год (всего 4602 статьи или около 27,5 млн слов). Применив латентное размещение Дирихле, авторы определили 126 ключевых тем, которые присутствовали в журнальных статьях за этот период, а также проанализировали, как эти темы менялись по значимости с течением времени. Объединив все 126 тем в несколько кластеров, они получили интересную картину (Рис. 2).
Рисунок 2. Журнал Philosophy of Science в диахронной перспективе
Malaterre, Chartier, Pulizzotto / Hopos, 2019
Результаты позволяют задокументировать различные эпизоды в истории философии науки: здесь и интерес к языку и логике в 1930–1970-е годы, стремительное развитие сюжетов, связанных с биологией, начиная с 1980-х годов, а также появление с конца 1990-х новых тем, посвящённых построению моделей и симуляций.
Исследование канадских учёных вдохновило другие подобные работы. В 2020 году Брайан Уэзерсон, профессор философии в Мичиганском университете и один из редакторов журнала Philosopher’s Imprint, провёл эксперимент с использованием латентного размещения Дирихле. Он проанализировав около 32 000 статей из 12 философских журналов, опубликованных в 1933-2013 годах, в том числе Analysis, Journal of Philosophy, Mind, Philosophical Review и др. (см. полный список в онлайн-версии книги).
Подобная работа, выполненная полностью на языке программирования для статистических исследований R, стала возможной благодаря функционалу Data for Research, предоставляемому онлайн-библиотекой научных журналов и книг JSTOR.
Свои выводы автор изложил в небольшой статье в издании Daily Nous. Важнейший из них заключается в том, что «существует огромная разница между работами конца XIX – начала XX века, которые современные аналитические философы воспринимают всерьёз, и работами, которые обычно появляются в журналах в те годы». В период с 1915 по 1941 годы практически не обсуждалась работа Бертрана Рассела «Об обозначении» («On Denoting»). Долгое время не обсуждались в журналах такие фигуры, как Джордж Эдвард Мур и Готлоб Фреге. Поздние работы Витгенштейна привлекают внимание современников, но «Логико-философский трактат» также остаётся незамеченным, а тема позитивизма «активируется» уже в контексте проблемы верификации.
Напротив, журналы начала века полны статей о различных формах идеализма. При этом, замечает исследователь, в британских журналах основное внимание уделяется сознанию и метафизике, а в американских — этике и политической философии. Многие выдающиеся авторы той эпохи сегодня более или менее полностью забыты. «Шэдворт Ходжсон опубликовал три десятка работ в ведущих журналах, но в наши дни о нём редко упоминают даже вскользь», — резюмирует Уэзерсон.
Ещё один пример применения алгоритма латентного размещения Дирихле — публикация 2021 года, вышедшая в журнале Science Education и посвящённая тематике этого журнала за последние почти сто лет (1922–2019). Авторы этого проекта исследовали около 5,5 тыс. статей, на основе которых они выделили 21 тему и проследили их «взлёты и падения» в диахронной перспективе (Рис. 3).
Рисунок 3. Журнал Science Education в диахронной перспективе
Odden, Marin, Rudolph / Science Education, 2021
Среди прочего, исследование отражает взлёт интереса к студенческой психологии в 1970–1990-е годы, сопровождавшийся повышенным вниманием к количественным методам. Как признают сами авторы, многие из выявленных трендов хорошо знакомы специалистам в отрасли, однако LDA впервые позволяет квантифицировать эти тренды. Похожим образом метод применялся для анализа трендов в онлайн-обучении и в библиотековедении.
В моём собственном недавнем исследовании в фокус LDA-алгоритма попал российский научный журнал «Платоновские исследования». Тематическая модель, построенная на основе архива этого журнала за последние десять лет, позволяет не только судить о важнейших трендах в отечественном платоноведении, но и количественно оценить вклад отдельных учёных в становление и развитие этих трендов (эта часть не вошла в опубликованную версию, но доступна в репозитории автора на GitHub).
В ходе обсуждения этого исследования на семинаре, организованном Институтом цифровых гуманитарных исследований СФУ 20 декабря 2023 года, был затронут важный вопрос о качестве «предлагаемых» LDA-классификаций. Тематические деления, созданные алгоритмом на основе статистических признаков, порой напоминают знаменитую классификацию Борхеса: «…животные делятся на принадлежащих императору, сказочных, нарисованных кистью из верблюжей шерсти или похожих издали на мух…». В самом деле, LDA-алгоритм ничего не «знает» о делении по единому основанию, и в каком-то смысле бросает вызов привычным способам организации действительности.
Но не стоит забывать и о том, что с цитаты из Борхеса начинается знаменитая «Археология гуманитарных наук» Мишеля Фуко (1969), в которой французский философ ставит вопрос о принципе упорядочивания, лежащем в основе любой классификации и, в свою очередь, обусловленном историческими обстоятельствами. В этом смысле метод латентного размещения Дирихле с его «стихийными» топиками продолжает традицию дискурсивного анализа в духе французских структуралистов.
«Помещая слова в набор дискурсивных практик, а не лингвистических правил, концепция дискурса Фуко освобождает нас от исключительного интереса к структуре языка и к тому, что эта структура передает, и ориентирует нас больше на на ассоциации различных слов, понятий или "топиков", которые образуют дискурс. С этой точки зрения, тематическое моделирование и модель "мешка слов", лежащая в его основе, могут быть использованы для выявления различных дискурсов в текстовых коллекциях на основе вероятностной совместной встречаемости слов в одном и том же дискурсивном контексте. Специалисты по информатике называют эти кластеры совпадающих слов "темами", мы же мы предпочитаем думать о них как о "дискурсах"», — пишут авторы исследования, посвященного «Энциклопедии» Дидро и Д’Аламбера.
Одиннадцать томов (1751–1772) и около 75 000 статей этого памятника эпохи Просвещения (доступные в электронном виде) стали основой тематической модели, которая позволила лучше оценить «дискурсивную акробатику» Дидро. Примерно 62 000 из этих статей снабжены тематическими метками согласно выработанной редакторами иерархической онтологии, однако, как подтверждает тематическая модель, эта классификация в ряде случаев носит затемняющий, а не проясняющий характер. Например, в статьях о городах могут скрываться биографии их великих граждан, а рубрика «грамматика» служит складом для всякого рода «вольнодумных» сюжетов, которые Дидро не хотел открыто маркировать.
Латентное размещение Дирихле в области политической истории и микроистории
Ещё одно возможное поле для применения LDA связано с анализом политической риторики. В 2018 году группа исследователей использовала этот подход для моделирования корпуса речей Национального учредительного собрания во Франции за 1789–1991 годы. Собрание, организованное в начале Великой французской революции, на протяжении двух лет выполняло функции законодательного органа. Около 40 000 речей, произнесенных в Собрании, оцифрованы и доступны онлайн.
Авторы использовали алгоритм латентного размещения Дирихле для того, чтобы выделить 100 тем, которые, в свою очередь, стали основой для количественной оценки «новаторства» и «резонанса» в речах отдельных ораторов. Для этого использовался такой показатель, как расхождение Кульбака-Лейблера, называемый также относительной энтропией. Его можно рассматривать как «меру удивления», или меру удалённости друг от друга двух вероятностных распределений.
Поскольку каждый документ — это как раз такое распределение, то можно сравнить документ с несколькими предыдущими, чтобы оценить его «новаторство» (novelty), и с несколькими последующими, чтобы оценить «мимолетность» (transience) затронутых в нем тем. «Резонанс» (resonance) авторы считали как «новаторство» минус «мимолетность»: если автор поднимает новую тему, и она остается в повестке, то выступление можно считать резонансным.
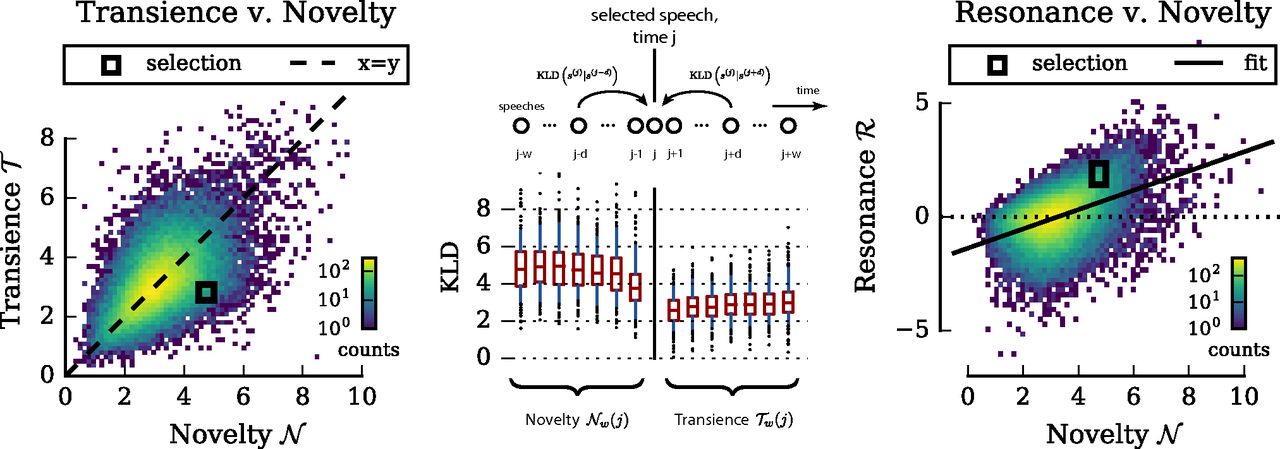{kind=link}
Самыми «новаторскими» и «резонансными» ораторами оказались такие радикалы, как Робеспьер и Петион. Напротив, Теодор Вернье и Арман-Гастон Камю показывают высокую долю новаторства, но низкий резонанс: исследователи это понимают в том духе, что их компетентные суждения по финансовым или правовым вопросам не раз позволяли «закрыть тему». Политические консерваторы Жан-Сифрен Мори и Казалес не «новаторствуют», но влияют на повестку.
Но метод LDA может быть применен и для моделирования политического ландшафта в менее драматичных и более приближенных к нам обстоятельствах. В одном из исследований для этого использовался корпус речей в новозеландском парламенте в 2003-2016 годах. Выделив 30 топиков (из которых были вручную отобраны 21 наиболее содержательных, таких как «налоги», «преступность», «образование», «Крайстчерч» и т.п.), авторы использовали их для построения нескольких бимодальных сетей.
Бимодальные сети, или сети аффилированности, подходят для тех случаев, когда необходимо отразить взаимодействие в рамках той или иной группы. В указанном исследовании член парламента считался «связанным» с темой, если она занимала не меньше 6,7% в его речах за год; это позволило выявить тех парламентариев, которых интересовали одни и те же темы (Рис. 5). В этом случае алгоритм латентного размещения Дирихле помог оценить, представители каких партий сильнее всего продвигали определённую повестку — и какие темы привлекали наибольший интерес.
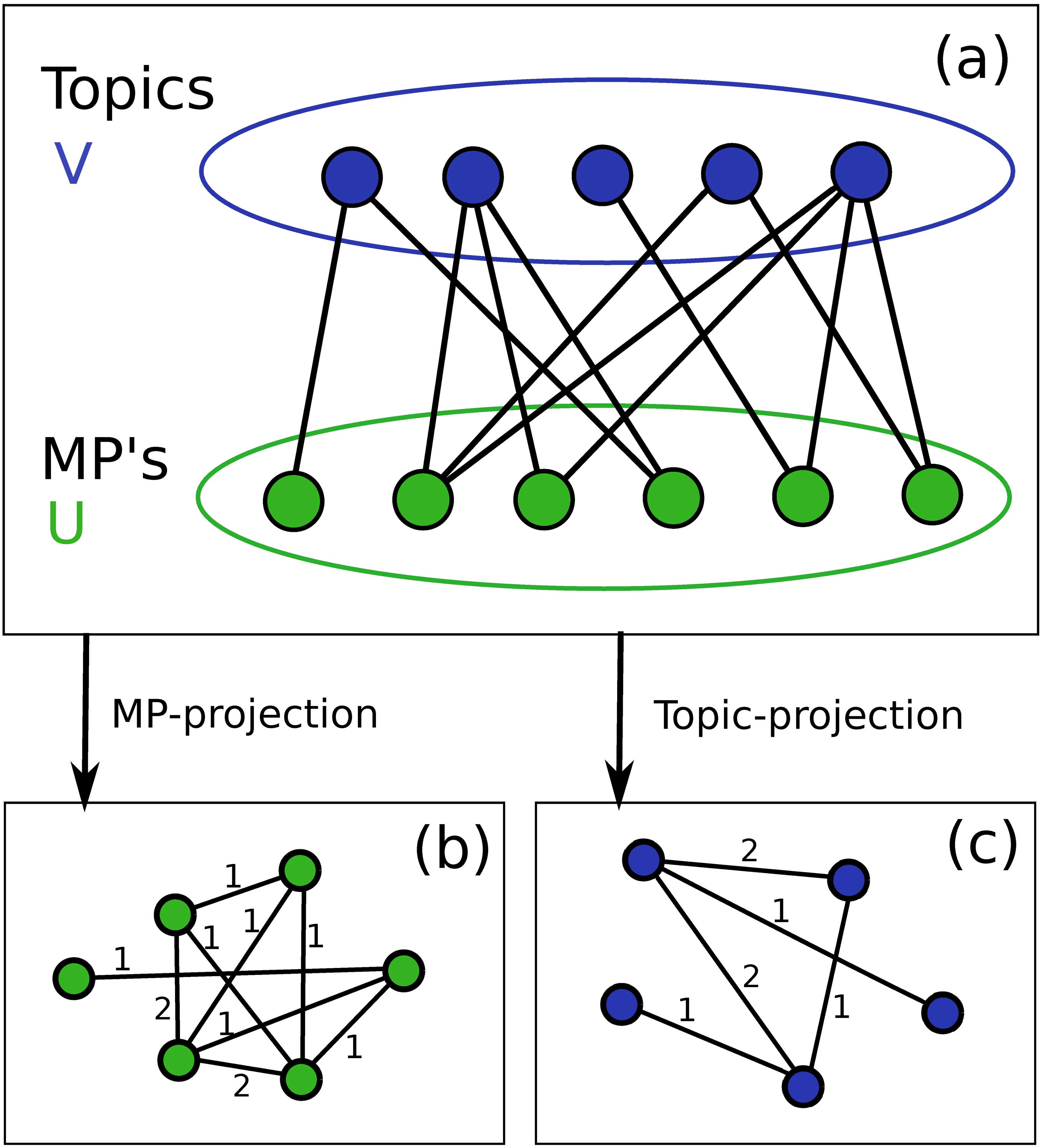{kind=link}
Стоит добавить, что возможности алгоритма LDA оказываются востребованы не только специалистами по интеллектуальной или политической истории, но и сторонниками «микроисторического» подхода, который не столько объясняет прошлое, сколько рассказывает о нём и раскрывает его с повседневной стороны.
Классическим примером такого рода подхода является проект по моделированию дневника американской акушерки Марты Баллард. За свою долгую и непростую жизнь (1735–1812) Баллард сделала около 10 000 дневниковых записей, в которых она рассказывает о принятых родах, о различных личных перипетиях и о многом другом. Эти записи легли в основу работы Лорел Тэтчер Ульрих «История повитухи», за которую она получила Пулитцеровскую премию.
В 2009 году дневники акушерки привлекли внимание американского Digital Humanities -исследователя Камерона Блевинса, который не только построил тематическую модель этих записей, но и подробно задокументировал процесс работы над проектом в серии постов. Обратим внимание на необычный способ проверки модели, который он использовал. Свои записи Баллард нередко начинает с сообщения о погоде, и один из LDA-топиков получил у Блевинса название «холодная погода». Сюда вошли слова «ветер», «холод» и т.п. Как выяснилось, эта тема «оживает» в записях в зимние месяцы; в то время как весной и летом Баллард больше говорит о своём саде, который очевидно доставлял ей большое утешение.
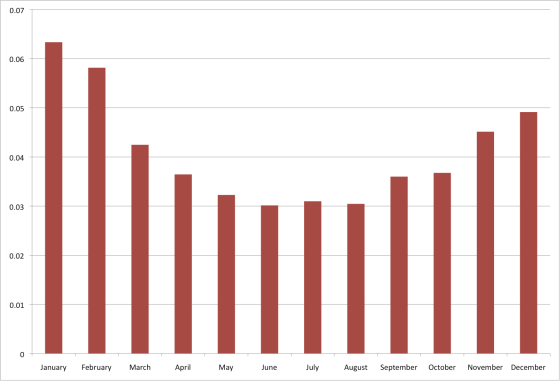{kind=link}
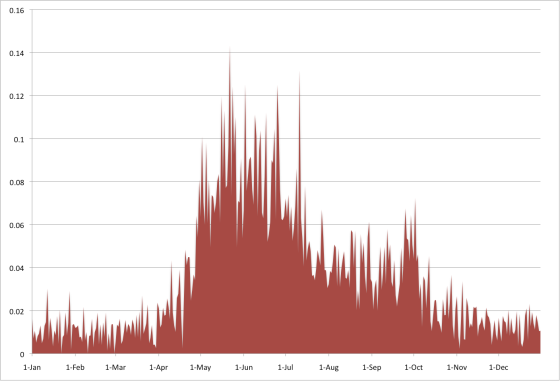{kind=link}
Латентное размещение Дирихле в области литературоведения и социологии литературы
В литературоведении и социологии литературы метод LDA применялся для анализа как художественной прозы, так и поэзии (в том числе «наивной поэзии»). Тематическое моделирование поэзии может дать интересный результат при сравнении различных литературных эпох. Так, в корпусе немецкой поэзии модель LDA успешно вычисляет взлёт «романтических» тем во второй половине XVIII века.
Но при работе с поэзией надо учитывать несколько особенностей. Дело в том, что алгоритм латентного размещения Дирихле «исходит» из того, что темы образуются словами, которые чаще встречаются вместе — а в поэзии это могут быть рифмующиеся слова! Поэтому в исследовании 2018 года, проведённом на корпусе испанских сонетов (более 5 000 сонетов XVI–XVII веков), в одном топике оказались llama, fama, ama, dama, cama и тому подобные «соседи».
Ещё одна особенность поэтической речи связана с её образностью. Из-за частого использования метафор, сравнений и других тропов слова нередко выступают из своего привычного контекста. Например, «морская тема» при ближайшем рассмотрении может оказаться вовсе не самостоятельной темой, а мотивом, то есть повторяющимся образом, в любовном или героическом сонете. В целом, когда речь идет о поэзии, LDA-топики далеко не всегда способны адекватно сообщить, «о чём» стихотворение.
При работе с большими прозаическими жанрами исследователей ждут другие трудности. Если при моделировании принять за «документ» роман целиком, то это приведёт к рыхлым и бессодержательным топикам. Поэтому дополнительная задача обычно заключается в том, чтобы правильно «нарезать» документы. В исследовании Мэтью Джокерса и Дэвида Мимно на корпусе англоязычных романов XIX века (всего 3 346 произведений) были выбраны отрывки в 1000 слов, что дало в итоге 631577 «документов» для анализа. На их основе с применением алгоритма латентного размещения Дирихле авторы выделили 500 топиков и дополнительно изучили связь между тематикой романа и гендерным профилем писателя.
В сочетании с другими методами топики, выделенные при помощи LDA, могут использоваться для предсказания жанра или поджанра произведения. В качестве примера упомянем исследование корпуса классической французской драмы, в ходе которого удалось вычислить топики, наиболее тесно связанные с жанром комедии, трагедии и трагикомедии.
Авторы изучили 391 произведение, написанное в период с 1630 по 1789 годы. (около 5,6 млн. слов); разделив тексты на отрывки, общим числом 5840, они подобрали модель из 60 тем, после чего оценили связь между топиками и различными поджанрами. Для этого использовались различные методы, в том числе — метод иерархической кластеризации, метод главных компонент и различные алгоритмы машинного обучения с учителем. Результаты применения метода главных компонент показаны на Рис. 7. Автор заключает, что литературные жанры — более, чем «просто проекция или социальный конструкт»; им соответствует «литературная реальность, которая может быть количественно оценена».
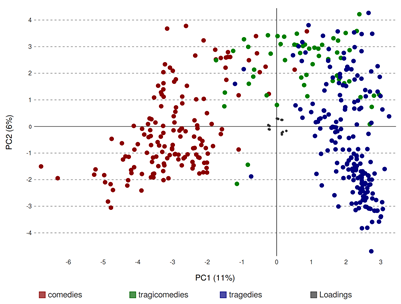{kind=link}
Наконец, метод использовался для изучения того, как в Дании распространялись идеи Чарльза Дарвина после публикации переводов его трудов, а также для поиска фольклорных мотивов в корпусе датской литературы.
Этот обзор не претендует на полноту, но позволяет говорить о том, что метод латентного размещения Дирихле — как самостоятельно, так и в сочетании с другими подходами, в том числе методами сетевого анализа или разными вариантами машинного обучения — используется в самых разных гуманитарных отраслях, помогая исследователям находить и квантифицировать закономерности в больших текстовых данных. Различные имплементации алгоритма существуют на языках Java, Python и R, а ознакомиться с ними подробнее можно, например, в магистратуре «Цифровые методы в гуманитарных науках» НИУ ВШЭ.
IQ